
Structure And Function Of Genes
It is estimated that there are about 30,000 genes located on 23 human chromosomes (as per Human Genome Project, 2001). Genes are arranged in a single linear order in the chromosome similar to arrangement of beads on a string. Genes are responsible for the determination of inheritable characters as well as characters that arise fresh in an individual (de novo) due to alteration in the structure or the function of a gene.
Two different kinds of genes exist in chromosomes, i.e., the structural genes and the control genes (regulatory genes). Function of structural genes is to synthesize specific proteins molecules, whilst the control genes regulate the synthesis and activity of structural genes. The function of regulatory genes is to promote or to inhibit the steps of transcription of a structural gene and later its translation into protein.
Molecular Structure Of Genes
DNA molecules are the main constituents of a gene. A structural gene can be defined as “a segment of DNA which contains the information (code) for synthesis of one complete and functional polypetide chain (or an enzyme).” Thus genes are nothing but blue prints or directories for protein synthesis.
The sequences of DNA in a structural gene should logically exist, and as was actually found, in a contiguous arrangement one after the other similar to the sequence for amino acids one after the other as they are situated in a polypeptide chain. It was further observed that there were many noncoding sequences which are called “introns” interposed, in addition to and in between the coding dequences termed “exons”.
Read and Learn More Genetics in Dentistry Notes
The number of introns in various genes is variable and sometimes it may so happen that introns may exist in more numbers than exons (coding sequences). Though introns are transcribed (vide infra), they are not included in mature mRNAs for translation in the ribosome.
The makeup of a structural gene not only contains the sequences of exons and introns but also possesses certain flanking regions at their ends. These flanking regions are important for regulation of gene expression.
The sequence of DNA that is transcribed into a single mRNA starting at a promoter and ending at a terminator is called a transcription unit of the DNA.
Sequences which control transcription constitute the flanking region at 5′ end of a gene. This region is called the promoter region and contains. “TATA” box and “CAT” box. TATA boxes are stretches of DNA within promoter regions that contain repetitive base pairings between Adenine and Thiamine. The presence of TATA box is essential for transcription initiation.
Downstream into the gene after the promoter region there is code for initiation of transcription or the start points of transcription. The sequences of strat points are followed by the first codon representing an amino acid and this codon is always the same irrespective of the gene and codes for the amino acid methionine (ATG).
This codon is followed by subsequent sequences of exons and introns of the gene. The 3′ end of the gene bears any of the UAA, UGA or UAG codons. These terminal codons or stop codons are transcribed onto the the mRNA and are essential for terminating the polypeptide chain synthesis during the process of translation at a later stage.

The TATA box consists of GGGCGGG sequences and CAT box CCAAT. These regions are indispensible for initiation of transcription as they bind to the transcription factors. At 3′ end of a gene, the flanking region consists of translation termination codon (TAA) which is followed by poly (A) cap codon (see transcription later).
The DNA transcription starts at 5′ end and ends at 3′ end of the coding strand or the sense strand of the gene. For initiation of transcription it is necessary that the promoter region should or the sense strand of the gene.
For initiation of transcription it is necessary that the promoter region should bind tot he enzyme RNA polymerase. However, in order to bind to this site the polymerase requires additional proteins called transcription factors. The transcription factors and related proteins bind to specific promoter regions and activate gene expression.
Some details of DNA Sequences
Both the nucleus and mitochondria contain DNA molecules. The count of total number of human genes is estimated at 30,000 genes implying that only a minor percentage of chromosomal DNA sequences are transcriptionally inactive and called Junk DNA having unknown functions. Several repetitive DNA sequences make up the junk DNA. DNA is divided into two classes, the genic DNA and extragenic DNA, for convenience of understanding.
Genic DNA
- Functional genes are usually present below the telomere with varying distribution of genes in different chromosomes, e.g. number 19 and 22 are gene rich while chromosome number 4 and 18 contain very few genes.
- Genes are small (single exon) or very large (79 exons). A single exon may contain many nucleotide base pairs.
- Most of human genes are single (single-copy genes that code most of the hormones, receptors, structural and regulatory proteins).
- In situations there may be more than one gene for the same function, e.g. many Alpja-globin genes are present on chromosome number 16 and many Beta globin genes are present in groups on chromosome number 11. Ribosomal RNA genes present on the short arms of various acrocentric chromosomes represent multiple genes for same functional output included in multigene families produced by gene duplication.
Extragenic DNA
These represent repetitive DNA sequences that are not transcribed (nongenic or extragenic) and called the Junk DNA. Their functions are not yet defined and may be of profound significance. The tandemly repeated DNA sequences and interspersted reprtitive DNA sequences are two vaireties of the DNA.
Tandemly Repeated Sequences are noncoding and can be found as satellite DNA, minisatellite DNA and microsatellite DNA. The satellite DNA is present near the centromere. The minisatellite DNA mainly consists of telomeric DNA of TTAGGG sequences that are 3 to 20 kilo-bases in length that protects the ends of chromosomes.
The hypervariability of these tandem repeats of sequences forms the basis of DNA finger-printing. The microsatellite DNA is formed by tandem repeats of a few (one to four) base pair sequences. These repeat base pair sequences are present throughout the genome.
Through the functions of these stretches of DNA are not clear, the hypervariability of minisatellite DNA forms the basis of finger printing. The telomeric minisatellite DNA plays a role in the stability of chromosomes and is lost with each cell division resulting in the senility and programmed death of the cell.
Genetic Code
Basically the genes are the blueprints or directories that instruct the synthesis of proteins. Proteins are made up of polypeptide chains which in turn are made up of amino acids. The amino acids are supposed to be linked together in a particular sequence in a polypeptide chain to be effective.
The numbers, types and arrangement of amino acids in a protein molecule determines the structure and function of that protein. Proteins are made up of various combinations of 20 amino acids.
A sequence of three bases on a DNA strand codes for one amino acid. There are four different types of nitrogenous bases in DNA (A, C, T and G).
In a situation if a single base codes for one amino aicd, 4 bases would code for just 4 amino acids (4 x 1 = 4). It now two bases are allowed to code for one amino acid in various combination, we get codes for only 16 amino acids (42 = 16) which is not enough for coding all the amino acids.
However if 3 bases are used in permutations to code for one amino acid then we get more than the adequate number of codes (43 = 64) with each amino acid designated more than a single code of three nucleotides (degenerative code).
Thus genetic information (codes) is piled up in the form of the genes (DNA molecule) represented by sequential arrangement of three bases that determine the make-up of proteins. This arrangement of three nucleotides is called the triplet code sequence.
“Transcription” (vibe infra) causes the transfer of these triplet codes from DNA to mRNA. The triplets of nucleotide bases in the mRNA molecule which code for a particular amino acid is called a codon.
The mRNA strand also contains chain initiation and chain termination codons. The initiation codon is present at the start of the mRNA and its sequence usually is AUG that marks the beginning of translation (polypeptide synthesis) in the ribosomal apparatus. The termination codon is present at the end of mRNA with sequences UAA or UAG. The synthesis of a polypeptide chain is terminated when a ribosomal apparatus reads through the stop codon.
All genetic codes as well as the protein manufacturing mechanisms are universal and found in all organisms synthesizing proteins. As such a cell can read a genetic code and translate it into the relevant protein irrespective of the source of the code. Human insulin can be produced in a large scale by bacteria that carry the human insulin coding gene put into the bacterial genome by genetic engineering. On the other hand viruses use host cell mechanisms for replication, used to our disadvantag.
The sequential arrangement of bases of a codon, if disturbed or chaged, may lead to the defective formation of protein causing disorders of metabolism, etc.
Transcription
Transcription is a process of synthesis of messengers RNAs where genetic information stored in the DNA of a gene is transmitted to the mRNA. This is the first step towards the formation of proteins.
Process of Transcription in Brief
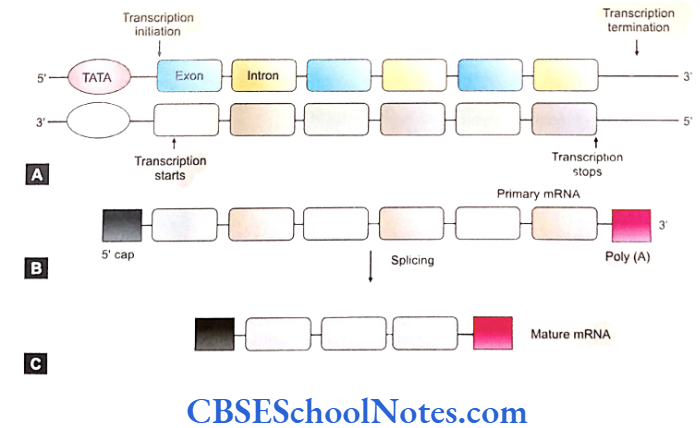
Two strands of DNA double helix are separated (denatured) from each other forming transcription bubbles (cf replication bubbles). This is acheived by the activation of transcription factors and attachment of RNA polymerase at the promoter region of the gene.
This kind of separation in DNA double strands can occur at more than one site throughout the genome during protein synthesis (interphase) or DNA replication (bbefore mitosis).
One of the strands is called the coding strand (sense strand) and an mRNA is always synthesized identical to the coding strand. An important thing to remember is that the mRNA can only be identical in sequence to the coding strand if the mRNA is assembled on the opposite DNA strand that is complementary to the coding strand and called the template strand (anti-sense).
An mRNA transcript is always formed on the template strand and a template strand is always ‘read’ from its 3′ to the 5′ ends.
The separation of strands takes place at the location of a particular gene that is to be transcribed. We just understood that the two DNA strands of a gene can be designed as a coding and a template strand. In context of a particular gene (DNA), the 5′ of the coding strand contains specific sequences called the promoter region. The process of transcription begins with the activation and blinding of transcription factors and the release of RNA polymerase at the promoter region of a gene.
Just a single strand of the DNA double helix is used for synthesis of mRNA molecule. The mRNA molecule is single stranded and synthesized by the enzyme RNA polymerase. With the help of this enzyme appropriate ribonucleotides are added to the mRNA chain sequentially.
The transcription of mRNA begins at its 5′ end and ends at the 3′ end of the molecule. Every base in a newly synthesized mRNA molecule is complementary to a corresponding base in the DNA of the gene (template strand). The cytosin (C) pairs with guanine (G), thymine (T) with adenine (A) but adenine pairs with uracil (U). Thus the information of a particular gene (coding DNA strand) is transferred tot the mRNA unchanged.
All the sequences of a structural gene are transcribed on to the mRNA molecule including extrons and introns; ones that do not make to the final transcriptory product.
Transcription is terminated by intrinsic and extrinsic mechanisms.
The G-C rich regions on the DNA give rise to hairpin bends on the RNA molecule as they are transcribed. This is called the intrinsic mechanism that causes a physical separation of the RNA from the DNA. The extrinsic mechanisms cause chain termination with Rho-factor enzymes that interact and inactivate the RNA polymerase at the RNA-DNA junctions.
Steps in the Process of Transcription
- Transcription begins at 5′ end and ends at 3′ end of the gene (the coding strand).
- The mRNA synthesis or so as to say, the assembly of its nucleotides begin on the template strand from the 3′ towards the 5′ end of the template strand.
- The mRNA itself is assembled from its 5′ end to the 3′ end.
- Each base in the newly synthesized mRNA molecule is complementary to a corresponding base in the DNA of the template strand and thus exactly has the same nucleotide sequence as that of the coding strand. Therefore information of a particular gene (DNA sequence) is transferred to the mRNA unchanged.
- There are discrete mechanisms to terminate transcription like the hairpin bend inducing intrinsic sequences on the DNA template or enzyme mediated terminated such as the Rho-factor, etc. These events cause the mRNA to detach from the template strand.
Some special events occur to the nascent mRNA molecule after its synthesis. Entire transcribed mRNA doesn’t participate in translation or protein synthesis. mRNA molecules are edited and pruned according to the requirement of protein synthesis in the cell during or after transcription.
- The intervening non-coding sequences (introns) are excised from the mRNA molecule. The exons spliced together to form a mature RNA molecule which is relatively shorter in length. This process is known as splicing (removal of introns by cutting them off and joining the ends of extrons).
- Molecule(s) of GTP gets attached to the 5′ end of the mRNA. Phosphate of the GTP is added to the terminal base of mRNA. This added Guanine structure is methylated and is called a methylguanine cap. This 5′ cap protects the mRNA from degradation and facilities the transport of mRNA to the cytoplasm. Similarly the 3′ end of mRNA is provided with a stretch of about 200 bases of adenylic acid called poly (A) tail which also protects mRNA from degradation and facilities the transport of mRNA to cytoplasm.
- The mRNA then migrates from nucleus to cytoplasm where it attaches to ribosomes for synthesis of protein (translation).
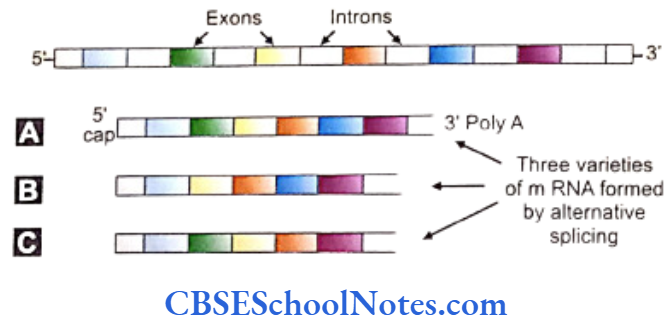
Alternative Splicing
The postulate of “one gene one protein or enzyme” theory can be doubted after demonstration of a far greater number of proteins (> 100,000) than existing number of genes (30,000 =- 35,000). This observation alternative splicing. The exons (protein coding areas) can be rearranged within the mRNA in different patterns.
The provision to leave out one or a few exons in between can drastically alter the translation product of the manipulated exon by changing the sequence of amino acids present in the resultant polypeptide chain. In this way different protein molecules are formed by a single gene.
Similarly the function of a protein can be modified after translation by phosphorylation or combination with other proteins. This process can experimentally be verified. Thus alternative splicing can explain the discrepancy of the number of genes vis a vis that of the proteins.
Translation
“Transcription” brings the genetic information for the synthesis of polypeptide chain from the nucleus (DNA) to the mRNA molecule. The cytoplasmic protein synthesizing machinery utilizes information on the mRNA to produce a protein molecule (polypeptide chain) in a cell. The translation apparatus consists of the following components:
Messenger RNA
Forms an important component of the translation machinery as it provides the coding sequence of bases determining the sequential arrangement of amino acids in the polypeptide chain. mRNA is translated from the 5′ to the 3′ end of the molecule.
Ribosome
Consists of a small and large subunit that come together on the mRNA strand to form a mature ribosome. The small unit reads the code on mRNA while the large unit aligns successive tRNA molecules and helps in the attachment of amino acids one upon the other by peptide bonds.
Transfer RNA
A given tRNA is attached to a specific amino acid by the enzyme aminoacyl-tRNA synthetase. A tRNA attached to its amino acids is called changed tRNA.
The codon on the mRNA binds to an anticodon on tRNA. This brings the attached amino acid into line for elongation of the growing polypeptide chain.
Translation consists of three stages, initiation, elongation and termination.
Initiation
- Beings at 5′ cap on the mRNA.
- The mRNA initiation complex is formed at the beginning of the molecule. This is fashioned by giving attachment to initiation factos (eIF4, eIF2, eIF3 and eIF5), small subunit of ribosome (40 S) and an initiator tRNA (with the UAC nucleotide sequence as the anticodon).
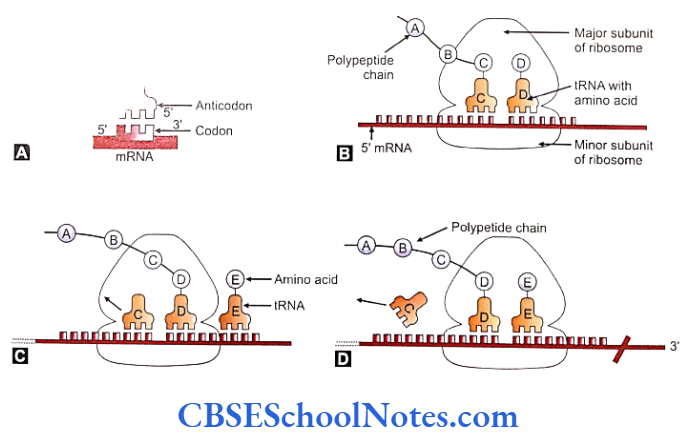
- The initiation complex moves along the mRNA towards its 3′ direction soon after the initiation complex is formed. It moves up till the first AUG nucleotide sequence is encountered. The AUG nucleotide sequence acts as start codon that signals the start of polypeptide synthesis.
- At this time point the large subunit (60 S) of ribosome gets attached on top of the small subunit. All other initiation factors are now released from the initiation complex.
- The AUG codon in the mRNA gets attached to the initiator tRNA (with UAC anticodon sequence) that moves in along with its amino acid methionine and occupies a domain inside the large subunit called the Peptidyl tRNA or simply the P site. The bonding is done with the help of hydrogen bonds.
Elongation
The immediate next three codons on the mRNA and the corresponding large subunit domain form the A site or aminoacyl site. Charged tRNAs called aminoacyl tRNAs land with their anticodons to attach with the corresponding codons at the A site. The methionine molecule is shifted from the tRNA of the peptidyl site (deacylated) to the aminoacyl site and bonded to the amino acid on the aminoacyl tRNA.
- The larger subunit of ribosome moves or translocates relative to the small subunit one codon further up towards the 3′ on the mRNA as the first step in elongation. This movement causes the A site become empty, the tRNA at the A site to shift to the P site and the deacylated tRNA dissociate from the ribosome.
- Next, the 30 S small subunit of ribosomes moves along the mRNA to align perfectly with the large subunit and activates the next triplet of the mRNA at the new A site.
- The next aminoacyl tRNA enters the A site.
- Polypeptide is transferred from the P site of the tRNA at the A site.
- Translocation moves the ribosome one codon at a time, releases the deacylated tRNA from the P site, places the tRNA from the A site (the peptidyl RNA) to the P site and keeps A site ready for the next aa-tRNA.
- The process continues and elongation takes place codon by codon.
Termination
Polypeptide synthesis is terminated when the ribosomal unit reads through the stop codon.
- On coming to the stop codon on the mRNA strand, the ribosome binds to a release factor (RF).
- The ribosome is unable to bind to any new tRNA now.
- The tRNA releases the polypeptide chain for further processing. This release is affected by the RF that recognizes the stop or termination codon and releases the chain from the ribosome.
- RF (the release factor) is consequently removed from the ribosome.
- The ribosomal subunits, 40 S and 60 S are separated from each other and are recycled.
- Folding of the polypeptide chains follows with their release from the ribosome.
Several ribosomes can move in tandem and at equal speeds on an mRNA strand placed at distances of about 80 nucleotides from each other (with a difference of about 25 amino acids between their polypeptide chains). The complex formed by aggregates of such ribosomes attached to a single mRNA is called a polyribosome or polyribosome.
As stated earlier a single gene can synthesize more than one protein by the process of alternative splicing. Further diversity in protein synthesis is effected commonly by chemical events such as phosphorylation, N-acylation, glycosylation, etc. or by its combination with other proteins – processes known as posttranslational modification.
Gene Expression And Its Regulation
The cells of the body are all not of a single type in structure or function though all of them are derived from a single cell, the zygote. It is quite interesting to find that at a given points of development there is spatial and temporal difference in the profiles of gene expression in each cell or a group of cells although all the cells contain equal and the same number of genes.
Even after complete development and differentiation, diverse population of cells show differential expression of genes, e.g. skin cells synthesizing keratin, neurons producing neurotransmitters, etc.
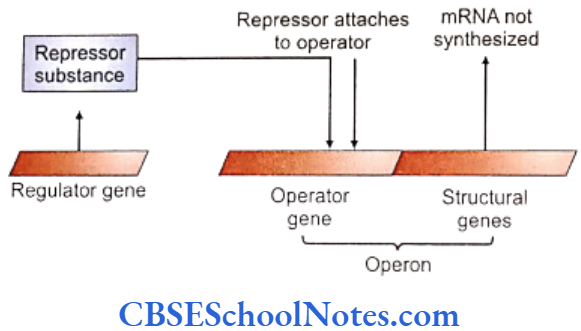
Basic Control of Gene Expression
Regulator gene and operator gene are the two different kinds of genes that govern the expression of other structural genes.
- The structural genes are under the control of operator genes which induce their transcription and are situated adjacent to the structural genes in a chromosome. The unit of the operator gene and structural genes is referred to as operon.
- The operator genes are further controlled by the regulator genes that are situated usually away from the operon. A repressor substance is synthesized by the regulator gene which inhibits or represses the operator gene that further inhibits transcription of the structural gene. Activation of a regulator gene suppresses proteins synthesis from the structural genes.
- A repressor substance may combine with certain enzymes or metabolites that prevent its action on the operator gene. Thus an operator gene comes out of the inhibition of the repressor and stimulates transcription in a structural gene to start protein synthesis.
- Transcription is more complex in the higher organism in terms of its regulation by transcription factors specific to certain DNA elements in the promoter regions that include the TATA, CAT boxes etc. DNA sequences, the “enhancers”, are known to increase the level of transcription. “Silencers” are regions on the DNA fragment that inhibit transcription.
Genetic Mutation, Its Types And Mutagens
Mutations are changes that occur newly in the genetic material of an individual and may be heritable. The ‘changes’ may range from an alteration in the smallest unit of a gene, i.e. in a nucleotide (in the coding and noncoding regions) to change in the gross morphology or number of the chromosomes.
- Gene mutation or a point mutation is a heritable change occurring in the structure of a gene.
- Chromosomal mutations are changes occurring at the level of chromosomes (gross structural or numerical changes).
- Mutation generally means a gene mutation and is seen across all living organisms. It is also the ultimate source of all genetic variations and accounts for species evolution.
- Mutations are essential for the long-term survival of any species and a species cannot acquire new genes without mutations. New traits that are necessary for adapting to the changing environment originate from mutations. Thus mutation provides raw material for evolution in a species. However, most mutations are damaging to the organism.
Some mutations are discussed below. An account of chromosomal anomalies are given in the next chapter.
Somatic and Germinal Mutation
- Mutations are called somatic mutations if they occur in somatic cells. Germinal mutations are mutations occuring in germ cells (egg or sperm).
- Somatic mutations can arise at any stage in the life of an individual.
- Somatic mutations cannot be transmitted to offsprings while germinal mutations are transmitted to the next generation as they occur in the gamete producing germ cells in the parents.
- Somatic mutations produce phenotypical changes in the particular affected individual while germinal mutations show-up in the subsequent generations.
- Somatic mutations give rise to genetically two different types of cell lines in the individual. Germinal mutations on the other hand don’t produce mosaic offsprings as all the cells of the child would contain the anomaly received through a defective gamete.
- Mutations of the germ line are heritable but somatic mutations are not.
A gene usually loses its function as a result of a mutation. At times a mutation may also lead to acquisition of a new function or increased level of gene expression.
“Loss of Function Mutation”
A complete inactivation of gene (elimination of the function of gene) or reduced activity of the gene can result from a mutation. This event or mutation is called a “loss of function mutation'”. This is also known as “knockout” or “null” mutation. Most of the loss of function mutations is recessive in the sense that these mutations need to be present in a homozygous state to exert the effects of the ‘loss’ (e.g. loss of an enzyme).
“Gain of Function Mutation”
Over expression of a gene (increase in gene product) or activation of a gene in a tissue where the gene in question is normally inactive, may result from a mutation. These mutations are called “gain of function mutation” and are dominant (a heterozygous state of the mutation can manifest the effects).
Presence of such mutations in homozygous stage manifest severe forms of disorder e.g. homozygous achondroplasia. A majority of such mutations lead to over expression of genes sometimes resulting in cancer.
Molecular Basis of Gene Mutation (Point mutation)
Alterations may happen in the arrangement of nucleotides in a DNA molecule even if the process of replication of DNA is very precise and stringently controlled. These changes are invisible through the microscope yet may have profound phenotypic effects in an individual. These smallest changes may involve an addition, deletion or substitution of a single nucleotide pair in the DNA molecule.
Point mutations (gene mutations) are of following types, namely (a) substitution mutations and (b) frame shift mutations with deletion or insertion.
Substitution
It is a common kind of mutation where a nitrogenous base of a triplet code of DNA is replaced by another nitrogeneous base. The alteration of the codon now codes for a different amino acid. Substitution of the base A in the GAG triplet code (coeding glutamic acid) by U alters it to a GUG codon (coding Valine) in the mRNA during transcription of Beta-globin chains of Hemoglobin leads to sickle cell anemia. The resultant defective B-globin polypeptide chains deform the RBCs by forming needle-like crystal aggregates in the hemoglobin.
A substitution mutation may not always be lethal as seen in the sickle cell disease. Nondeleterious mutations are known as silent mutations. However a gene mutation may be beneficial at times as seen in sickle cell mutation that imparts resistance to malaria.
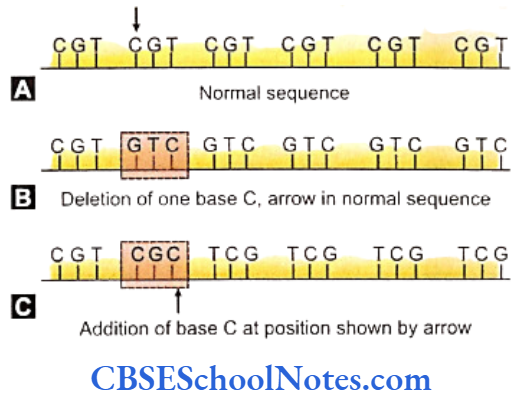
Frame Shift Mutation
An insertion or deletion of a nuitrogenous base in between the sequences in DNA or mRNA results in a frame shift mutation. The mutation leads to shifting of the reading frame or apparatus that reads the sequences of the codons. This shifting is caused by the insertion or removal of bases in the sequence. Such mutations may occurs during transcription (DNA mutation) it during translation (mRNA mutation).
Frame shift mutations are often lethal because all the triplet codes beyond the point of mutation are misread by the apparatus as the system can read only set of 3 bases at a time. Highly altered proteins are synthesised. Single mutations are more lethal than a triple contiguous mutation as a triple substitution omits a single amino acid whereas a single base mutation disturbs the reading frame usually resulting in termination of the process.
Mutagens
Majority of mutations usually are unprompted and called spontaneous mutations. These mutations hardly have a detectable cause but are attributed to errors in steps during DNA replication. Mutations can rise also due to exposure to certain environmental agents. These agents are known as mutagens.
Mutagens can be classified into two groups:
Physical and Chemical mutagens: Physical agents such as high temperature is are known mutagenic agents in animals. Many chemicals like mustard gas, formaldehyde, benzene, thalidomide and LSD are considered mutagenic in animals.
Radiations: Known causes of mutations include both natural and artificial ionizing radiations. Cosmic rays of the sun are sources of a natural ultraviolet radiations. The other sources of natural radiation are the radioactive elements like thorium, radium and uranium present in the earth.
X-rays, gamma rays, alpha and beta rays (particles) and neutrons are artificial sources of radiation. Radiations may cause breaks in chromosomes and chromatids. These breaks involve sugar phosphate backbone of the polynucleotide strands resulting in severe anomalies.
Mechanism Of DNA Repair
The frequency of DNA damage by chemicals and radiations are quite high evaluated at the rate of about 10,000 throughout the genome in 24 hours. The damages are automatically repaired by specific and precise molecular mechanisms without any residual effects.
- The enzyme DNA ligase repairs small nicks in the DNA strand.
- Repair is executed with the help of the enzyme AP endonuclease at places of a base-pair loss.
- Repair is executed in steps at sites with a large damage in the DNA strand. The damaged area is first cleaved by the enzyme endonuclease. Next the damaged portion is removed by the enzyme exonuclease. A newly synthesized DNA strand is then inserted with the help of the enzyme DNA polymerase. The break is finally sealed by DNA ligase enzyme.
- DNA fragmented by ultraviolet light is repaired by the products of at least eight genes.
Summary
- A gene is defined as “a segment of DNA which contains the information (code) for synthesis of one complete polypeptide chain”. Thus a gene provides instructions for building a specific protein.
- The control genes regulate the activity of structural genes.
- The DNA portion of a structural gene not only contains coding sequences for amino acids (exons) but also contains noncoding sequences (introns).
- A structural gene contains flanking regions at their ends. These regions are important for regulating the affairs of the gene.
- Proteins are made up of polypeptide chains. Polypeptide chains are constructed of specific sequences of amino acids.
- A sequence of three bases on DNA strand codes for one amino acid. The sequence is called the triplet sequence.
- A DNA strand constituting a structural gene contains all the sequentially arranged codes for amino acids that combine to form a complete polypeptide chain.
- Transcription defines the transferring of the blueprint in the DNA (coding and noncoding sequences) of a gene to messenger RNA.
- As the base pairing is unique in selectivity, the information of DNA strand is transferred to mRNA unchanged identical to the coding strand.
- Control genes regulate the activation of structural genes.
- Control genes are of two different kinds, i.e. the regulator genes and the operator gene.
- The unit of an operator gene and a structural gene is called an operon.
- Repressor substances are synthesized by regulator genes. These substances inhibit the operator gene which further inhibits structural genes.
- Certain metabolites may combine with a repressor substance to inactivate them. The operator gene is thus released of inhibition and gets activated.
- Regulation of transcription is more complex in higher organisms.
- Changes occurring in the genetic material of an individual is defined as mutation. Mutations may be heritable.
- Mutation may occur in a gene (point mutation or gene mutation) or it may occur in a chromosome (chromosomal mutation).
- Point mutations are either substitution mutations or frame shift mutations.
- Point mutations are due to an addition, deletion or substitution of a single nucleotide in the DNA sequence of a chromosome.
- Mutations in somatic cell are called somatic mutations and in germ cell are called germinal mutations.
- Environmental agents causing mutations are called mutagens.