
The Earth In The Solar System Exercises
Question 1. Answer the following questions briefly:
- How does a planet differ from a star?
- What is meant by the ‘Solar System’?
- Name all the planets according to their distance from the sun.
- Why is the Earth called a unique planet?
- Why do we see only one side of the moon always?
- What is the Universe?
Answer:
(1). Difference between a Planet and a Star

(2). Meaning of Solar System: The celestial bodies consisting of the sun, its planets, satellites, asteroids, meteoroids and dust particles form the Solar System.
Read and Learn More CBSE Solutions For Class 6 Social Science
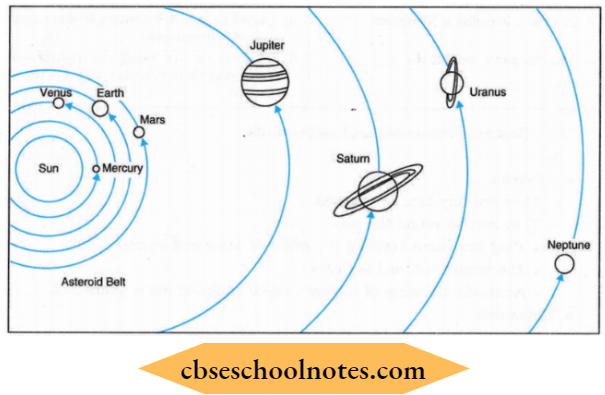
(3) Planets according to their distance from the sun:
- Mercury
- Venus
- Earth
- Mars
- Jupiter
- Saturn
- Uranus
- Neptune
(4) The Earth is called a unique planet because of the following reasons:
- Only the earth has conditions favourable for life; in the form of humans, animals and plants.
- Earth has favourable or suitable temperatures for life. It is neither too hot nor too cold.
- Earth’s surface has water and air. No other planet in the Solar System has water and air, essential for the survival of humans, plants and animals.
- Life-giving oxygen gas is found only on the earth.
(5) We see only one side of the moon always because ofthe following reasons:
- The moon revolves around the earth in 27 days.
- The moon spins on its axis exactly in 27 days.
- So, we see only one side of the moon always.
(6) Universe: We see millions and millions of stars, planets, satellites, asteroids, and meteoroids forming galaxies. Innumerable galaxies form the universe.
Question 2. Tick the correct answer.
(1) The planet known as the “Earth’s Twin” is
- Jupiter
- Saturn
- Venus
Answer: 3. Venus
(2) Which is the third nearest planet to the sun?
- Venus
- Earth
- Mercury
Answer: 2. Earth
(3) All the planets move around the sun in a
- Circular path
- Rectangular path
- Elongated path
Answer: 3. Elongated path
(4) The Pole Star indicates the direction of the
- South
- North
- East
Answer: 2. North
(5) Asteroids are found between the orbits of
- Saturn and Jupiter
- Mars and Jupiter
- The Earth and Mars
Answer: 2. Mars and Jupiter

Question 3. Fill In The Blanks:
(1) A group of forming various patterns is called a ___________.
Answer: Stars; constellation
(2) A huge system of stars is called __________.
Answer: Galaxy
(3). ________ is the closest celestial body to our earth.
Answer: Moon
(4). __________ is the third nearest planet to the sun.
Answer: Earth
(5) Planets do not have their own _________ and ____________.
Answer: Heat; light
Question 4. During a vacation visit a planetarium and describe your experience in the class.
Answer: Things we saw at the planetarium.
- Working model of the solar system.
- Information regarding the number of days taken by planets for rotation and revolution.
- Huge telescope.
- A short movie on stars and galaxy.
- Information about eclipses.
Question 5. Do you wonder why we can’t see the moon and all those bright tiny objects during the daytime?
Answer:
Because the light of the sun in the time is so bright that we cannot see these tiny bright shining objects in the night sky.
Question 6. What do animals and plants require to grow and survive?
Answer:
To grow and survive, animals and plants require heat and energy, oxygen, water and food.
Question 7. Has any Indian landed on the moon?
Answer:.
No Indian has ever landed on the moon. However, Indian astronaut Rakesh Sharma and Indian-American astronauts Kalpana Chawla and Sunita Williams have been to space; but they did not land on the moon.
Question 8. Do you see a whitish broadband, like a white glowing path across the sky on a clear starry night?
Answer:
Yes. A whitish broad band is like a white glowing path across the sky. It is a cluster of stars, known as the Milky Way. It is our galaxy.
The Earth In The Solar System Very Short Types Questions And Answers
Question 1 Why is Venus considered as ‘Earth’s Twin’?
Answer:
Venus is considered as ‘Earth’s Twin’. Because its size and shape are similar to that of the Earth.
Question 2. Why is the Earth called ‘Blue Planet?
Answer:
From the space, the earth looks blue because its two-thirds surface is covered with water. The earth is, therefore, called a Blue Planet.
Question 3. What is a constellation? What is the other name of the Saptarishi constellation?
Answer:
Constellation: In the night, the stars form various patterns and designs. A group of stars forming a particular design is called a constellation.
Saptarishi (design of Seven Stars) is one such constellation (Sapta-seven, rishi-sages). The constellation Saptarishi forms a part of Ursa Major, also called Small Bear.
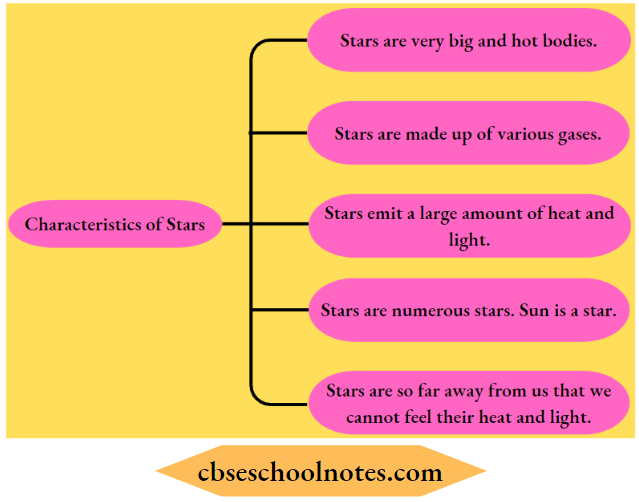
Question 4. Why do the stars look so tiny and we do not get their heat and light?
Answer:
Stars seem tiny as they are very far away from us, and so we do not feel their heat and light.
Question 5. Which planet has now been termed a Dwarf planet’?
Answer:
Pluto has been termed a dwarf planet by the International Astronomical Union.
Question 6. Define a Geoid.
Answer:
A geoid is a sphere with its ends flattened at the poles.
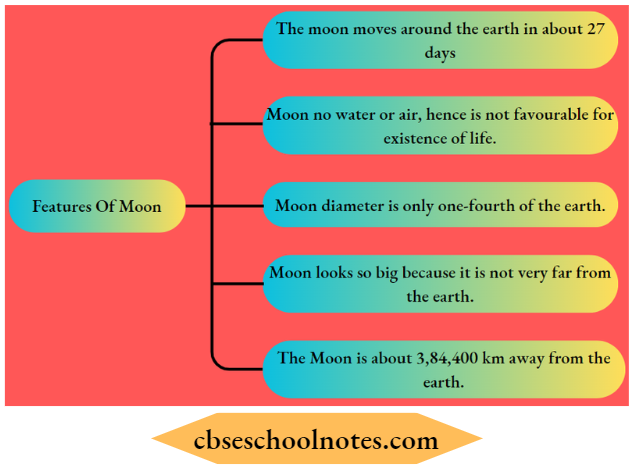
Question 7. What is the distance between the earth and the moon?
Answer:
Moon is about 3,84,400 km away from Earth.
Question 8. How is the universe formed?
Answer:
Many galaxies like the Milky Way combine to form the universe.
Question 9. How can we locate the position of the Pole Star with the help of the Saptarishi constellation?
Answer:
An imaginary line, passing through pointer stars, always points towards a pole star. Thus we can locate the position of the pole star by this line which passes through the pointer stars.
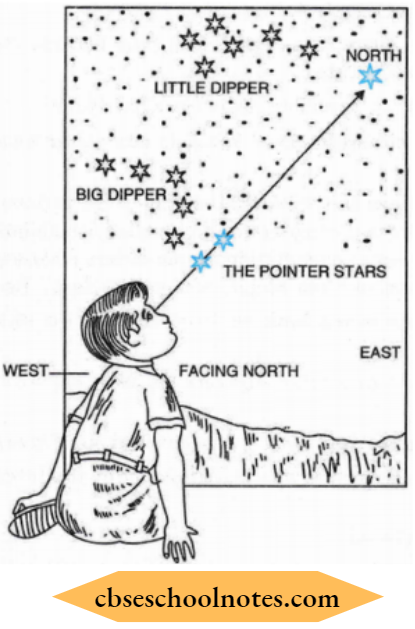
Question 10. Which is the biggest member of the solar system? Discuss it.
Answer:
The sun is the biggest member of the solar system. It is about 150 million km away from Earth. It is in the centre of the solar system. It is made of extremely hot gases and is the source of all heat and light (energy).
It is a million times larger than our Earth. It is the source of the pulling force that binds the solar system. The earth would be cold and lifeless without solar energy.
Question 11. How does the moon appear different each night?
Answer:
The moon revolves around the Earth. Its position about the sun changes every day. It has no light of its own, it only reflects the light of the sun.
The moon neither decreases nor increases, in reality, it only appears changed because of differences in light falling on it every day.
Question 12. What is an orbit?
Answer:
All the planets of the solar family revolve around the sun in elongated paths, known as orbit.
Question 13. Why does the moon not have conditions favourable for life?
Answer:
The moon does not have conditions favourable for life because of the following reasons:
It has neither water nor air.
Question 14. Why do we see shadows on the moon?
Answer:
- The moon has mountains, plateaus, plains and depressions on its surface.
- In the reflected light on the earth, these features look like shadows. Hence, we see shadows on the surface of the moon.
The Earth In The Solar System Short Type Questions And Answers
Question 1. Write the major features of the moon.
Answer:
The moon is the only natural satellite of the earth.
Question 2. State some characteristics of stars.
Answer:
Question 3. What are the characteristics of some of the celestial bodies like the earth and the moon?
Answer:
Some of the celestial bodies like the earth and the moon do not have their heat and light. They only reflect the light of the sun.
- The earth is a planet of the sun.
- Whereas the moon is a satellite of the earth.
Question 4. What is a galaxy?
Answer:
A galaxy is a huge system of stars, clouds of dust and gases. The white glowing path of stars across the sky is called the Milky Way galaxy.
We in India call it Akash Ganga. It has millions of stars very close to one another. Many galaxies make up the Universe.
Question 5. Name the largest and the smallest planets. Which planets are bigger and which are smaller than the Earth?
Answer:

Question 6. How would the earth be affected if it is taken:
- Too nearer or
- Too far from the Sun?
Answer:
- If the earth is taken too near to the sun, its temperature will grow higher since it will get a greater amount of heat. It will become unfit for habitation as it would be a hot desert.
- If the earth is taken too far from the sun its temperature will fall. It will get a lesser amount of heat. It would become an ice-bound desert; and would be unfit
for human habitation.
Question 7. Which two planets are closest to the sun? Write about them.
Answer:
Mercury is the nearest and closest planet to the sun. It takes about 88 days to complete its revolution around the sun. It is very hot and is the smallest planet.
Venus is the second closest and is called “earth’s.twin”. It is very similar to Earth in shape and size.
Question 8. What is the position of our planet, the earth, in our solar system?
Answer:
The Earth is the third nearest planet to the sun. Based on its size it is the fifth largest planet. It is slightly flattened at the poles, and has a bulge on the equator, it is described as a Geoid.
Long Type Questions And Answers
Question 1. Distinguish between a Satellite? and a Star.
Answer:
Distinction between a satellite and a star:
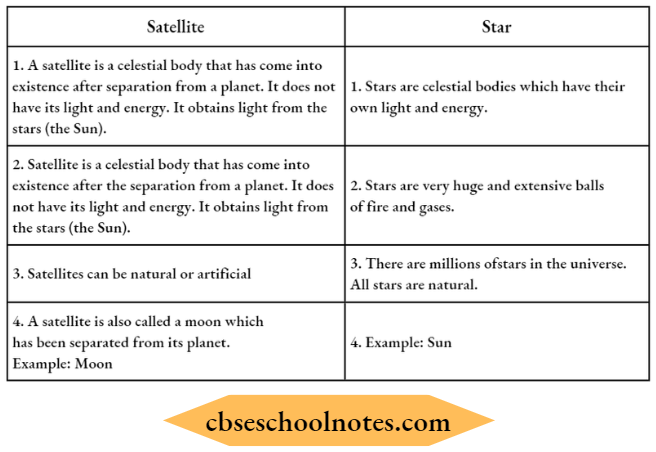
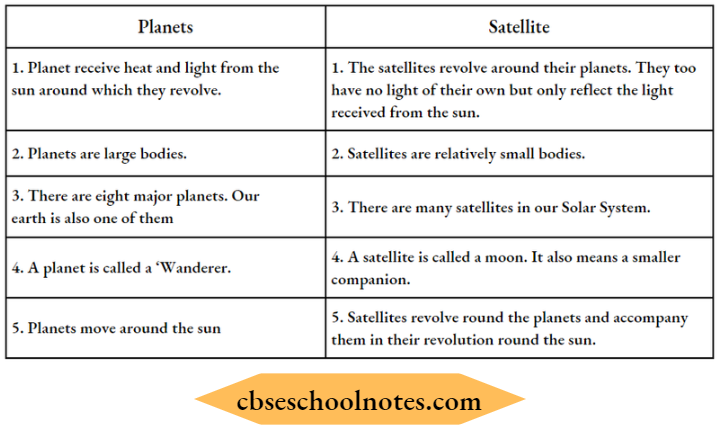
Question 2. Differentiate between a Planet and a Satellite.
Answer:
Difference between a Planet and a Satellite:
Question 3. Describe asteroids and meteoroids.
Answer:

Question 4. Explain some features of the earth.
Answer:

Question 5. Describe the sun and its planets with the help of a diagram.
Answer:

The Earth In The Solar System Multiple Choice Questions Answers
Question 1. What are celestial bodies?
- The sun
- The Moon
- All the shining bodies in the sky
- All of these
Answer: 4. All of these
Question 2. The celestial bodies which, have their heat and light are called:
- Planets
- Stars
- Satellites
- All of these
Answer: 2. Stars
Question 3. The celestial bodies which do not have their heat and light but are lit by the light of the stars are named as:
- Stars
- Planets
- Both (1) and (2)
- None of these
Answer: 2. Planets
Question 4. The word ‘planet’ has been derived from the word ‘planetai’ which is a:
- Latin word
- German word
- Greek word
- English word
Answer: 3. Greek word
Question 5. The earth is called a unique planet as:
- It is neither too hot nor too cold
- There is the presence of air and water
- It has oxygen, light and supporting gases
- All of these
Answer: 4. All of these
Question 6. The earth is called a blue planet because of the presence of:
- Water
- Deserts
- Mountains
- Plateau
Answer: 1. Water
Question 7. How many days moon take to revolve around the Earth?
- 29 days
- 30 days
- 27 days
- 31 days
Answer: 3. 27 days
Question 8. Meteoroids are made up of:
- Dust
- Pieces of rocks
- Gases
- None of these
Answer: 2. Pieces of rocks
Question 9. What is called a cluster of millions of stars, shining white in the starry sky?
- Stars
- Planets
- Milky Way galaxy
- Satellites
Answer: 3. Milky Way galaxy
Question 10. What makes the universe?
- Millions of galaxies
- Millions of stars
- Earth
- Satellites
Answer: 1. Millions of galaxies
The Earth In The Solar System Objective Type Questions And Answers
Question 1. Fill in the blanks with appropriate words:
(1). The Saptarishi constellation is also known as _________ constellation.
Answer: Small bear
(2). The Pole star indicates the ___________ direction.
Answer: North
(3). Asteroids are found between the orbits of ___________ and ___________.
Answer: Mars and Jupiter
(4). The Hindi word for full moon night is _________ and new moonlight is called ________.
Answer: Poornima and Amavasya
(5). ________ has recently been described as a dwarf planet.
Answer: Pluto
(6). ___________, ___________ and __________ have rings around them.
Answer: Jupiter, Saturn, Uranus.
Question 2. Match the contents of Column A with Column B.
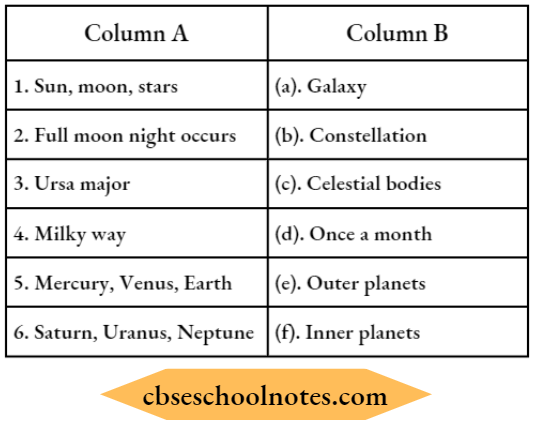
Answer: (1)-(c), (2)-(d), (3)-(b), (4)-(a), (5)-(f), (6)-(e)
Question 3. State whether the given statements are true or false.
(1). All the planets revolve around the sun in a fixed circular path.
Answer: False
(2). Moon does not have conditions favourable for life.
Answer: True
(3). The Sun is a star.
Answer: True
(4). Earth is the only planet to have artificial satellites.
Answer: True
(5). Geoid shape is a perfect sphere.
Answer: False